When I got satellite TV last year from Shaw, one of the channels to which I got access in the package to which I subscribe is CNBC. CNBC has some very interesting programming and documentaries. Some remind me of why I got hooked on cable channels over the traditional network channels in the early nineties, and are comparable to series such as the (excellent) Bill Kurtis’ American Justice on A&E and take your pick of any the mainstays on The Discovery Channel like Frontiers of Construction, Mega Ships, Ultimate Engineering, and the like.
One of the features of Shaw Satellite is that there is a “Guide” screen that shows the current programming as well as future programming; so far — for the purposes of this entry, in fact — the furthest into the future I have ever checked is a touch over 24 hours.
What I am wondering is how much CNBC actually cares to accurately report their schedule in advance to the cable carriers who arguably are their bread and butter, put aside of course their advertisers. I am obviously aware that I am perhaps at best on the fringes of CNBC’s prime target audience, since I’m not a stock broker or a financial analyst.
Of course a small part of me is wondering about how much effort Shaw puts into requiring accurate reporting of scheduling from the stations that they broadcast, at least to the extent that they have power over such matters and wish to try to exert such power over the stations they broadcast. I am aware that Shaw is but one player in the Canadian market, and that CNBC is a player in the much larger Amercian market.
But in researching this post I have come to the conclusion that Shaw probably has little to do with the issue at hand.
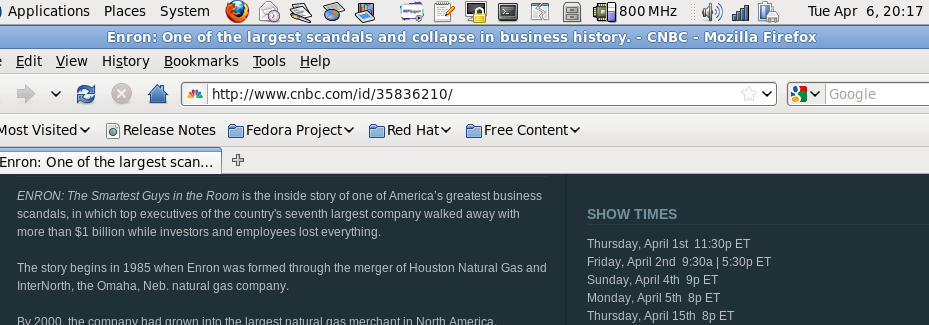
Over the last few months, I have occasionally wandered over to CNBC because of a scheduled show that sounds interesting, usually as a result of channel surfing. And what do I find but a substitution program, however interesting it may be. I can count at least four such times prior to this past weekend that the actual program is different from the announced program. This phenomenon caught my attention again this past Thursday, April 01 2010, after 10:00pm when I “wandered” over to CNBC, interested by the announcement of “Enron: The Smartest Guys in the Room”; what was in fact being broadcast was a one hour documentary called “Ultimate Fighting — Fistful of Dollars”. Note that from now on I am referring to times in Eastern Daylight Time.
My conclusion was a presumption that the occurrence was no doubt a semi-regular occurrence given the sporadic nature of my noticing this at random intervals over time; the perceived regular occurrences seemed a bit beyond the usual occasional errors due to technical difficulties such as:
– transcription errors due to a clerk for either party entering the wrong information into the schedule;
– the station expecting to secure the appropriate broadcast rights in time to a given show or episode but not managing to, hence the switch;
– the station losing a last-minute scuffle with the show’s copyright holder(s) and having to show something else as a result;
– the station realizing, after sending off the planned schedule, that there was an accounting error and they had used up their broadcast rights for the show or particular episode, or neglected to renew it;
– a major news event making a last-minute substitution appropriate, such as a market crash or the sudden arrest of the CEO of a major multinational;
– etc.
In this case I’m usually discussing a repeat of, say, their Wal-Mart documentary instead of their Marijuana production in the US documentary, both being otherwise very interesting documentaries, but neither being of particular greater value or time-sensitive interest over the other. However in a couple of cases live market shows have been actually shown, which I am aware are CNBC staples.
So for the past few days I have been, without going much out of my way, noticing the schedule versus the actual show being broadcast on CNBC. (I of course won’t bother mentioning the times that I checked and the schedule was accurate, or could have but didn’t check.)
Saturday April 03 2010 at 11:30am, the schedule announced the half-hour “Sexy Beach Bodies” (I’ll presume it was a show about Beach Culture, Suntan Lotion, and possibly Skin Cancer. Or an infomercial on how to get ripped in 28 days or less 🙂 ) The actual show was “Cruise Inc.”, a documentary about the cruise industry, which, being an hour-long documentary, began at 11:00am.
Saturday April 03 2010 at 10:00pm and 10:30pm, the schedule said “Till Debt Do Us Part”, a Canadian personal finance reality TV series about various couples’ train wreck spending habits heading straight for more debt after bad, and how to get out of it. The actual show was a one hour documentary called “Game Changers” about innovative entrepreneurs who were very influential in their field.
As I was writing this post on Sunday afternoon, I checked CNBC again, for my amusement and to add to the case either way:
Sunday April 04 2010 at 5:00pm was announced as “Paid Programming”, while the announced show for 5:30pm was “Relieve Back Pain”. The actual show from 5:00pm to 6:00pm was a one hour documentary called “The Money Chase: Inside Harvard Business School”.
As I was editing this post on Monday evening at about 9:45pm, I happened upon CNBC and decided to amuse myself again:
Monday April 05 beginning before 9:30pm and ending at 10:30pm, the schedule said “Enron: The Smartest Guys in the Room” followed by “Till Debt Do Us Part” at 10:30pm. “Squawk Box” was at 9:45pm. At 10:00pm, “Cash Flow” came on.
Now in the defense of either party, strictly speaking — and I mean, during the same period I only noticed the following example in the course of my TV consumption, and at the same time do not recall in the past several months noticing another such occurrence outside of CNBC — the phenomenon isn’t just limited to CNBC: On Saturday, April 03, 2010 at 9:00pm, I was watching KCTS PBS Seattle and was watching “As Time Goes By” (Yes, I am a boring person with nothing better to do on a Saturday evening!) The schedule was accurate about the show and time, but the episode description was off, so it’s not strictly speaking limited to CNBC. However for the moment I’m willing to classify this occurrence within one of the excuses listed above, and in any case I don’t recall observing the phenomenon for other stations, which generally have been accurate within my experience.
But here’s the clincher: At about 8:30pm on Saturday, April 03 2010, CNBC had a commercial announcing “Enron: The Smartest Guys in the Room” for Sunday, April 04 at 9:00pm to 11:00pm, so at that time I checked the Shaw schedule for Sunday evening, and sure enough the schedule listed the Enron documentary. At about 9:57pm on Sunday, April 04, finishing another show on another channel, I checked CNBC: It seemed as though “Squawk Box” was finishing, although I held judgement for five minutes, never having watched said show and figuring that maybe it could be a business update during an end-of-the-hour commercial break. Funny enough, at 10:00pm, they had a show called “The Run Down”, a live news show providing daily reporting on Asian markets, which are twelve to fourteen hours ahead of the New York Markets. Despite the currency of the live information, it seems to me that such a show would not trump the former in a last-minute showdown, certainly not from what they seemed to be showing in the first few minutes. However, to look at the opposite side of the same coin, this is the kind of show that, being another component of the station’s bread and butter, would be a matter of “Well duhhh, we always have those shows on, why is the programming guy announcing in the Enron documentary?” making me wonder why the Enron documentary would be listed at that time; but no matter, whether CNBC intended to show one then quickly changed its mind, or didn’t bother to check whether the “listings announcement” guy is doing their job properly, the problem is the same: There seems to be a rampant problem with the concordance between the Announced Broadcast Schedule, and the Actual Broadcast Schedule.
Come On, CNBC, what’s up with your programming? You’ve proven that at least not all the inconsistencies belong to Shaw’s clerks taking too many coffee breaks! In fact, it seems to be that were it not so blatantly obviously due to a case of laissez-faire on your part, I dare say there could be a bit of “Bait and Switch” going on.
So my message for you CNBC, is a paraphrase of the March Hare’s message to Alice: “Announce what you’ll be broadcasting, and broadcast what you announce.”